We have worked with non-technical founders building AI products across fintech, healthcare, education, and consumer. Some arrived with clean slates. Most arrived mid-crisis, burning cash on the wrong architecture, arguing with an outsourced team about scope, or sitting on a demo that impressed investors but could not handle real users. The mistakes repeat. Here are the nine we see most often, along with how to avoid each one.
If you are early enough to avoid them, this post saves you real money and real time. If you are already deep in one of these, the fix is usually simpler than you think.
Mistake #1: Building AI for the Sake of AI
The pitch deck says “AI-powered.” The product roadmap centers on machine learning. But when you strip away the buzzwords, the core problem does not require AI at all.
We have seen this pattern play out repeatedly: a founder builds an “AI-powered” version of something that could be handled with a weighted scoring formula, a rules engine, or a simple API integration. The founder spends months and significant capital on ML engineering before anyone asks whether the problem needed ML in the first place.
The tell is usually in how the founder describes the AI component. If the explanation is vague (“it makes it smarter” or “investors expect it”), there is no AI product. There is a product that might use AI as one component.
How to avoid it: Before writing a line of code, answer one question: what does AI do here that a simpler approach cannot? If the answer is not specific and measurable, build the product first. Add AI where it creates real value. A product that solves the problem without AI is infinitely better than an AI product that does not ship.
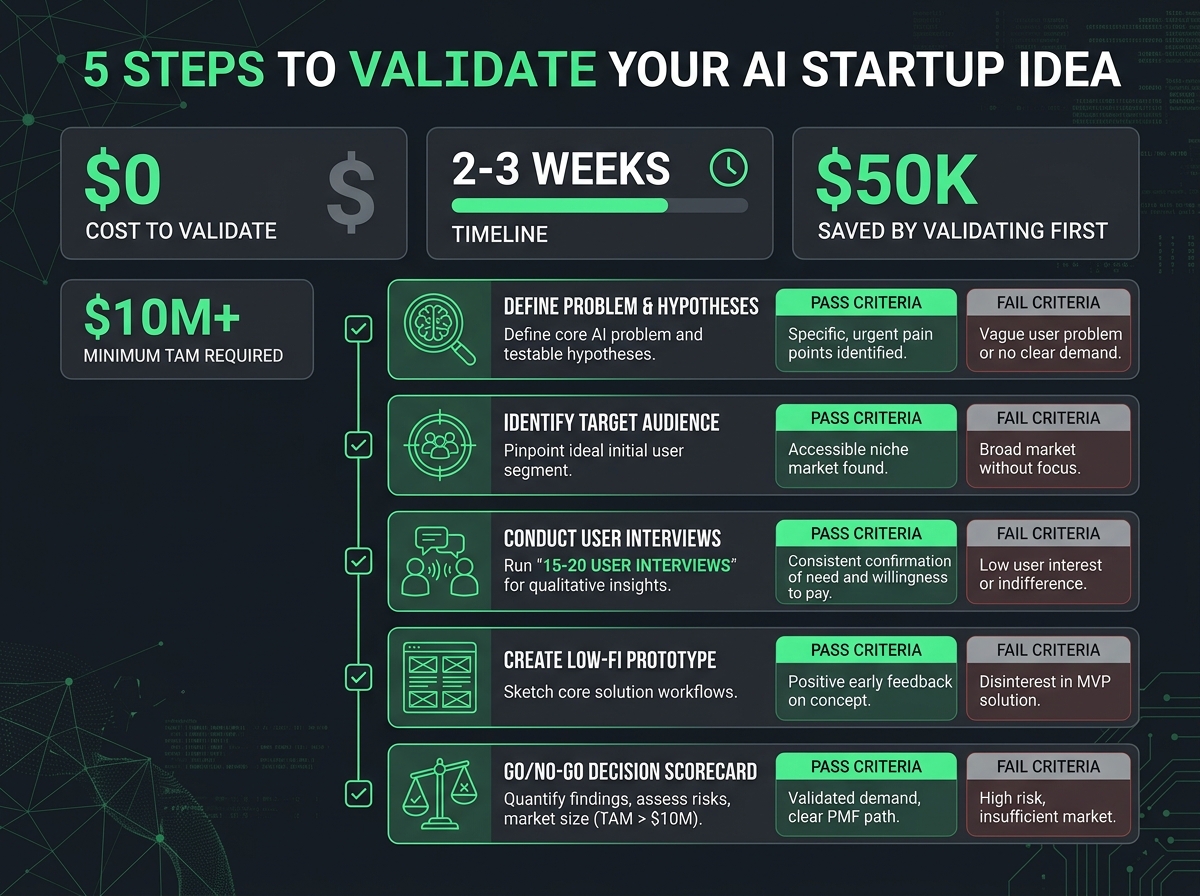
If you are still validating your concept, our guide to validating an AI startup idea walks through the process step by step.
Mistake #2: Ignoring Data Quality Until It Is Too Late
AI products live or die on data. Not data volume. Data quality. Founders underestimate this consistently because the demos work fine with clean sample data.
The pattern is always the same. The AI performs well in testing with curated inputs. Then real users show up. They type with errors, use unexpected formats, mix languages, describe multiple things at once, and submit data the team never anticipated. Accuracy drops significantly, sometimes by 20 or 30 percentage points between testing and production.
We saw this firsthand when building products in construction tech. Real-world data from job sites (blurry photos, inconsistent angles, varying lighting conditions) is nothing like the clean datasets you test with in the lab. We had to build our data pipeline to handle the messiest possible inputs from day one.
How to avoid it: Test your AI with the messiest data you can find from day one. Ask real users to interact with a prototype before you build the full product. If your AI cannot handle real-world input quality, you need a data pipeline before you need a product.
Mistake #3: Over-Engineering the AI Architecture
First-time AI founders tend to architect for a scale and complexity they do not have yet. Multi-model pipelines, custom vector databases, fine-tuned models, real-time inference engines. All before the first paying customer.
The pattern: a founder builds a multi-model pipeline with specialized components, self-hosted infrastructure, and a custom evaluation framework for a product that could be built with a single API call to a foundation model and well-crafted prompts. The over-engineered version takes months longer, costs significantly more to maintain, and often produces comparable output quality.
In 2025 and 2026, foundation models are good enough for most MVP use cases. The complexity should match the stage. If you do not have paying users yet, you do not need a custom training pipeline.
How to avoid it: Start with the simplest architecture that could work. One model. One API. Managed infrastructure. Add complexity only when you have evidence (user feedback, performance metrics, scale requirements) that demands it. If you are unsure what your AI MVP should look like, our AI MVP cost breakdown gives you the full picture.
Mistake #4: Underestimating AI Infrastructure Costs
Traditional SaaS has predictable infrastructure costs. You pay for servers and databases. AI products add API usage fees, vector database hosting, GPU compute, and model monitoring tools. These costs scale with usage in ways founders do not anticipate.
The founder who budgets a few hundred dollars per month for infrastructure is consistently surprised when real usage drives that number into thousands. Every API call to a foundation model costs money. Every document processed, every query answered, every analysis run. Each action has a per-unit cost that scales linearly with users.
We tell every founder the same thing: model your AI costs per user action before you set your price. Know what it costs to process one document, one query, one analysis. If you do not build usage-based pricing or usage caps into the product from day one, every new user is a net cost.
How to avoid it: Model your AI costs per user action before you set pricing. Know your per-unit economics. Build usage-based pricing or usage caps into your product from day one. Our AI MVP cost breakdown includes real infrastructure cost ranges by product type.
Mistake #5: Skipping Validation Because “The AI Works”
A working model is not a validated business. The AI can produce excellent outputs and still fail as a product, because nobody wants those outputs, or they are not willing to pay for them, or the delivery mechanism is wrong.
The pattern looks like this: a founder builds an AI tool that produces genuinely impressive output. The technical capability is real. But the product is pointed at the wrong user, the wrong workflow, or the wrong delivery format. The AI works. The product does not. And by the time the founder realizes the product needs repositioning, months of development have been pointed in the wrong direction.
Validation is not about whether the AI works. Validation is about whether someone will pay for what the AI produces, in the format you deliver it.
How to avoid it: Talk to 15-20 potential customers before building. Show them the AI output, not a polished product, just the raw output. Ask: “Would you pay for this? How would you use it? What format do you need it in?” The answers reshape your product before you waste money building the wrong thing. Our validation guide covers this in detail.
Mistake #6: Hiring an ML Engineer When You Need a Full-Stack Developer
Non-technical founders hear “AI startup” and immediately start recruiting machine learning engineers. ML engineers are expensive, specialized, and often the wrong hire for an early-stage AI product.
The pattern: a founder hires a senior ML engineer as their first technical hire. Months later, the ML engineer has built impressive model prototypes in Jupyter notebooks. But the startup still has no deployed product, no user-facing interface, no API, no authentication, no payment integration. They needed a full-stack developer who could ship a product, not a researcher who could train models.
How to avoid it: In 2026, AI coding tools like Lovable, Bolt, Cursor, and v0.dev let founders build a surprising amount of the product themselves. Frontend, basic workflows, integrations. What you actually need first is not an ML engineer but help with the genuinely hard parts: AI infrastructure, architecture, production hardening, and scaling. Build what you can with AI tools. Bring in expert help, whether that is a full-stack developer, a technical co-founder service, or a focused engagement for architecture and infrastructure, for the pieces those tools cannot handle.
Mistake #7: Not Planning for Model Drift and Retraining
AI models degrade. User behavior changes. The underlying LLM providers update their models, sometimes breaking your prompts overnight. Founders who treat the AI layer as “done” after launch are always surprised when accuracy drops months later.
We experienced this at scale when building fintech products. When you depend on AI models in production, handling thousands of real transactions, model maintenance is not optional. The models that work today will not work the same way six months from now, even without any code changes on your end.
How to avoid it: Budget 15-20% of your initial build cost annually for model maintenance. Set up monitoring that tracks output quality metrics, not just uptime, but accuracy, relevance, user satisfaction. When OpenAI or Anthropic ships a new model version, test your prompts against it before migrating. Treat your AI layer like a living system that needs ongoing care, not a feature you ship and forget.
Mistake #8: Building a Demo Instead of an MVP
Demos impress. MVPs work. The difference is the gap between a controlled presentation and a product that handles real users, edge cases, errors, and scale. We see founders mistake one for the other constantly.
A demo uses curated inputs, pre-selected examples, and controlled conditions. An MVP handles bad inputs, shows loading states, catches errors, works on different devices, and has real authentication. The gap between “this works in a demo” and “this works with real users” is often months of engineering.
The most dangerous version of this: raising money on the strength of a demo that is not a real product. Investors think there is a working product. The founder knows there is not. That gap creates enormous pressure and erodes trust when it surfaces.
How to avoid it: Build an MVP from day one, not a demo. An MVP handles bad inputs gracefully, shows loading states, catches errors, works on mobile, and has user authentication. It does not need to be pretty, but it needs to be real. If your AI only works in a controlled demo environment, you do not have a product yet. You have a proof of concept.
Mistake #9: Giving Away Too Much Equity for Technical Help
Non-technical founders often feel they have no negotiating power. Someone offers to build their AI product for a large chunk of equity, and they take it because the alternative feels like not building at all. This is the most expensive mistake on this list.
We have seen founders give 25-40% equity to a developer for what amounts to a few months of execution work. At a $10M outcome, that equity is worth millions. At a $50M outcome, tens of millions. The work was real. The pricing was not.
Execution is not partnership. A few months of development, even excellent development, is not worth the same as years of building the company alongside you. The math only becomes obvious in hindsight, after the cap table is set and the relationship has evolved past renegotiation.
How to avoid it: Pay cash for technical execution whenever possible. Build what you can yourself with modern AI coding tools (Lovable, Bolt, Cursor, v0.dev) and bring in expert help for the hard parts: AI infrastructure, architecture, production hardening, scaling. A focused engagement for those pieces gets you a production-ready product with zero equity dilution. Reserve equity for true co-founders, people who will spend years building the company alongside you. A technical co-founder as a service gives you co-founder-level thinking at execution pricing.
Ready to build without the costly mistakes? Book a free strategy call with Downshift. We will help you figure out what to build yourself, where you need expert support, and what it will actually cost. No equity. No surprises.
The Common Thread
Every mistake on this list comes from the same root: building before understanding. Understanding the problem before choosing AI. Understanding the data before building the pipeline. Understanding the user before designing the product. Understanding the costs before setting the price. Understanding the equity math before signing the term sheet.
The founders who avoid these mistakes are not smarter or more experienced. They are more disciplined about the order of operations. Validate first. Build the simplest thing that works. Add complexity when the data demands it. Pay cash for execution and save equity for partnership.
If you are a founder building an AI product, the single best investment you can make is getting experienced guidance on the parts that actually matter: architecture, AI infrastructure, production hardening, and scaling. Build everything you can with modern AI tools. Get expert help on the hard parts.
Talk to Downshift. We build alongside founders, not for them. We will tell you if your idea needs AI, what you can build yourself, which architecture fits, and where you need expert support. No pitch, just an honest conversation between founders.
FAQ
What is the biggest mistake AI startups make?
Building AI for the sake of AI, using machine learning when a simpler approach solves the problem. We see founders spend significant capital on ML engineering before anyone validates that the problem requires ML at all. Before committing to an AI architecture, ask: what does AI do here that a rules-based system, a weighted formula, or an API call cannot? If the answer is not specific and measurable, reconsider your approach.
How do I avoid over-engineering my AI MVP?
Start with the simplest architecture that could work. Use a single foundation model API (OpenAI, Anthropic, Google) instead of building a custom pipeline. Use managed infrastructure instead of self-hosting. Add complexity only when you have user feedback or performance data that demands it. We have seen founders cut infrastructure costs by 90% and development time by months by simplifying their AI architecture.
What is model drift and why should founders care?
Model drift is when your AI’s performance degrades over time without any code changes. User behavior shifts, data distributions change, and underlying model providers update their APIs. A system that was highly accurate at launch can degrade significantly within six months if the data no longer reflects current conditions. Budget 15-20% of your initial build cost annually for model monitoring, prompt optimization, and retraining to stay ahead of drift.
When should an AI startup pivot?
Pivot when your validation data says to, not when the AI fails, but when users do not want the outputs the AI produces. A working model with no market demand is a science project, not a startup. Signs you need to pivot: fewer than 30% of beta users return after first use, users request fundamentally different outputs than what you built, or your unit economics require 10x your current usage to break even. Pivoting on positioning or delivery mechanism is cheaper and faster than pivoting on core technology.